官方网站")
官方网站")
官方网站")

2025岁首火星电竞CHINA,DeepMind发了一项策划,论断让许多东说念主傻眼——处理汉文的AI模子,参数限度比英文模子高出23%。换句话说,一样的任务,汉文模子不错用更少的"脑细胞"完成。这不是什么民族见地叙事,是硬邦邦的算法数据。
一个用了三千年的笔墨系统,尽然在最前沿的东说念主工智能领域把英文比了下去。这事儿怎样评释注解?
每个汉字,皆是一个压缩包
1984年,有个叫冯志伟的学者作念了一项测算,论断是:一个汉字平均能装下9.65比特的信息,而一个英笔墨母,只好4.03比特。
这两个数字放在沿途,差距大到有点不讲道理——一个汉字顶上英笔墨母的两倍多。
承接国开大会,五种官方话语的文献要同步分发,汉文版每次皆是那摞纸里最薄的。一样一份实质,汉文版平均比英文版少三分之一的纸。这不是排版问题,是笔墨自身的信息密度不一样。
但为什么汉字能装这样多?

这事得从平素话的"先天劣势"提及。平素话的音节,全部加起来就400来个,哪怕声调全算进去,也就1300个控制。这数字少得恻然——比较之下,汉语的祖宗中古汉语有快要4000个音节,同音字表象少得多。
音节数越压缩,同音字就越多。粗略举个例子,"xi"这个读音,背后对应了十几个中古汉语里十足不同的字,全挤在统一个发音里出不来了。于是平素话的字典里,同音字的密度是惊东说念主的。
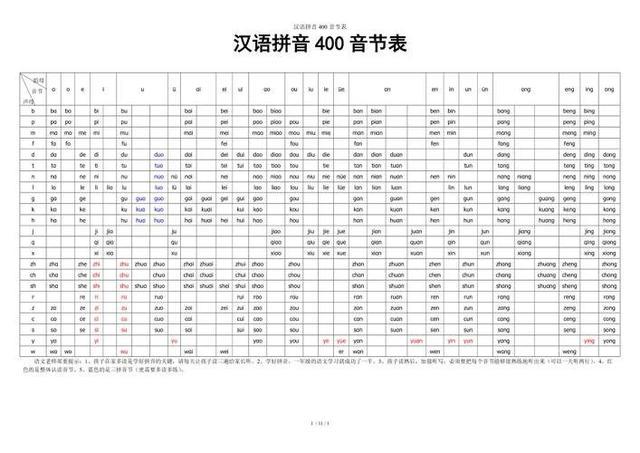
语音系统"偷懒"了,视觉系统就得补位。
汉字的处理决策是:在一个方块里同期塞进三件事——体式、读音、真义。义符告诉你这个字八成是什么类别的东西,声符提供读音痕迹,统共这个词字给出精准含义。英文是条形码,从左读到右,一个字母接一个字母列队;汉字更像二维码,落魄控制同期传递信息,统共这个词是并行处理的。
被语音系统"逼"出来的高密度,反而成了书面系统最大的上风。
密度变现:读得快,铭刻少,用得久
信息密度高,最平直的平允是念书快。
1995年,有策划者用眼动仪盯着汉文读者和英文读者的眼球转,数据出来挺异常想:汉文读者每分钟能处理580个字符,英文读者是380个单词。磋商到一个英文单词节略等于1.5个汉字,换算下来,汉文阅读的等效速率比英文快了快要四成。
用核磁共振扫汉文读者和英文读者的大脑,限度也不一样。英文阅读主要激活左脑,走语音通路——眼睛看到字母,先在脑子里拼出读音,再从读音里捞真义,是串行处理。汉文阅读激活双侧脑区,视觉通路平直把字形映射到语义,无谓经由读音这一层中转。

用大口语说:看到"马",汉文大脑平直蹦出马的画面;英文大脑看到"horse",要先念一遍,再意料马。
偏旁部首是这个系统的中枢计关。当代常用汉字里,独特80%皆是形声字,义符厚爱告诉你这个字属于什么范围。看到"鲈、鲤、鲫",就算不坚强这几个字,"鱼"字旁照旧预报了它们皆是鱼类。英文的bass、carp、salmon三个词,在字面上莫得任何共同特征,不坚强等于不坚强,猜皆没法猜。
义符的存在,让汉字读者在十足解码之前就能计算后续实质,这是阅读速率快的认剖判理。
词汇这件事上,差距就更较着了。掌抓3500个常用汉字,表面上不错读懂98%的书面材料。英文辞书呢,光是牛津英语辞书就收录了独特30万个单词,统共这个词英语话语里的词汇量猜测独特百万。英语每年还在新增几万个词,历久学不完。

这事的历史根源是1066年。诺曼东说念主打下英国之后,法语成了贵族话语,300年里法语词汇多量涌入英语,和底本的腹地词并存。于是英语里,动物名用英语(cow、sheep),但肉类名用法语(beef、mutton)。两套词汇系统叠在沿途,谁也没法替代谁,只可硬背两遍。
汉文造新词是"积木逻辑":激光=激+光,盘算推算机=盘算推算+机器,坚强基础字就能推理新词含义。英文造新词是"外来引入"或"全新创造",laser是五个英文单词首字母的缩写,computer和"盘算推算"十足莫得字面关连,必须孤苦牵挂。3500块积木能拼出实在统共东西,但别东说念主的百万个零件,每一个皆要单独学。
三千年的信息压缩,正在通过算法考证
汉字记载的是真义,不是发音。这小数,决定了它能撑多久。
李白写的"床前明蟾光",唐朝东说念主这样读,咱们今天如故这样读,真义十足没变。汉字系统的踏实性建立在"真义锚定"上,发音不错变,字形和字义保持不动。
英文就不一样了。英文记载的是发音,但发音一直在跑。15世纪到17世纪,英语阅历了一次叫"元音大推移"的语音改动,统共长元音像多米诺骨牌一样挨个移位。乔叟期间的"fine"读法,和今天十足不同;古英语《贝奥武甫》,当代英国东说念主提起来就跟看外语一样。莎士比亚距今不外400年,今天读他的原版脚本皆得配堤防书。

汉字从甲骨文到今天的楷书,字形变了,但字和字之间的组合关系从来没断过。"明"字,无论哪个朝代写,皆是"日"加"月",三千年没变过。这是东说念主类历史上独逐个套持续使用独特三千年、今东说念主还能平直读懂的笔墨系统。
但汉字不是莫得过危险。投入工业期间,铅字印刷出问题了。英文只需要26个字母的字模,汉文需要几千个,排版限度差得不是小数半点。那段时刻,"汉字无法相宜机械化期间"是谨慎的常识分子忧虑。
弯曲点在1975年。北京大学的王选团队运转策划汉字激光照排,处理决策是用数学概括来刻画字形,压缩比达到500:1——把几千兆的字形信息压进几兆内存,比西方同类手艺早了快要十年。1979年,第一张用这套系统付梓的汉文报纸样张出来了,铅字期间结束,汉字完成了工业化检阅。

再然后等至今天这个所在了。DeepMind那项策划说汉文AI模子限度高23%,字节高出的测试走漏中笔墨幕的生成速率是英文的1.8倍,华为云的数据是汉文NLP模子参数不错比英文缩减28%。原因说穿了很简便:汉文每个字承载的信息量大,一样的真义需要的token更少,模子无谓花那么多参数去消化冗余信息。
三千年前,平素话音节太少,字形系统被动在方块里塞进更多信息,意外中造出了一套信息压缩系统。三千年后,这套系统碰上了神经集聚,发现彼此的逻辑高度吻合——偏旁部首本来等于内置的语义标签,AI的分层特征索取不吃力就能平直用上。
这不是文化自爱感,是不错写进论文里的算法事实。咱们每天唾手打出来的这几千个方块字,扛过了铅字期间的手艺考验,当今又在算法期间把账算总结了。
